Secuencia de ADN
 | Este artículo o sección necesita referencias que aparezcan en una publicación acreditada. Busca fuentes: «Secuencia de ADN» – noticias · libros · académico · imágenes Este aviso fue puesto el 13 de junio de 2011. |
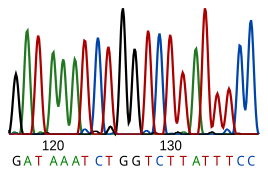
Una secuencia de ADN, secuencia de nucleótidos o secuencia genética es una sucesión de letras representando la estructura primaria de una molécula real o hipotética de ADN o banda, con la capacidad de transportar información.
Las letras son A, C, G y T, que simbolizan las cuatro subunidades de nucleótidos de una banda ADN - adenina, citosina, guanina, timina, que son bases covalentemente ligadas a cadenas fosfóricas. En el típico caso, las secuencias se presentan pegadas unas a las otras, sin espacios, como en la secuencia AAAGTCTGAC, yendo de 5' a 3' de izquierda a derecha.
Una sucesión de cualquier número de nucleótidos mayor a cuatro es posible de llamarse una secuencia. En relación con su función biológica, que puede depender del contexto, una secuencia puede tener sentido o contrasentido, y ser tanto codificante o no codificante. Las secuencias de ADN pueden contener "ADN no codificante".
Las secuencias pueden derivarse de material biológico de descarte a través del proceso de secuenciación del ADN.
En algunos casos especiales, las letras seguidas de A, T, C y G se presentan en una secuencia. Esas letras representan ambigüedad. De todas las moléculas mostradas, hay más de una clase de nucleótidos en esa posición. Las reglas de la Unión Internacional de Química Pura y Aplicada (IUPAC).
Notación
| Símbolo[1] | Descripción | Bases representadas | Complemento | ||||
|---|---|---|---|---|---|---|---|
| A | Adenina | A | 1 | T | |||
| C | Citosina | C | G | ||||
| G | Guanina | G | C | ||||
| T | Timina | T | A | ||||
| U | Uracilo | U | A | ||||
| W | Weak (enlaces débiles) | A | T | 2 | W | ||
| S | Strong (enlaces fuertes) | C | G | S | |||
| M | aMina | A | C | K | |||
| K | Keto | G | T | M | |||
| R | puRina | A | G | Y | |||
| Y | pYrimidine | C | T | R | |||
| B | excepto A (B después de A) | C | G | T | 3 | V | |
| D | excepto C (D después de C) | A | G | T | H | ||
| H | excepto G (H después de G) | A | C | T | D | ||
| V | excepto T (V después de T y U) | A | C | G | B | ||
| N | cualquier Nucleótido (sin vacío) | A | C | G | T | 4 | N |
| Z | Zero | 0 | Z | ||||
Véase también
- Ácido desoxirribonucleico
- Polimorfismo de nucleótido único
- GenBank
Referencias
- ↑ Nomenclature Committee of the International Union of Biochemistry (NC-IUB) (1984). «Nomenclature for Incompletely Specified Bases in Nucleic Acid Sequences». Consultado el 4 de febrero de 2008.
| Control de autoridades |
|
|---|
 Datos: Q863908
Datos: Q863908 Multimedia: Nucleic acid sequence / Q863908
Multimedia: Nucleic acid sequence / Q863908









